
Part 1 of 4 in the “What Event-Driven Architecture Actually Demands” series
Your manager just announced it in the standup: “We’re moving to event-driven architecture.” The team nods enthusiastically. You’ve watched the YouTube videos, the confrence sessions, blog posts (mine included). You know the buzzwords: decoupling, scalability, resilience.
What nobody mentions: your three-component system is about to become fifteen. Your debugging sessions are about to triple in length. And if you don’t get three specific things right, partition strategy, schema governance, and idempotency, you’re building a distributed time bomb.
After running event-driven systems handling billions of events and CDC pipelines that absolutely cannot drop data, here’s what actually separates success from production hell.
About This Series
This is Part 1 of a four-part series on what event-driven architecture actually demands in production:
- Part 1 (you are here): Is Event-Driven Architecture Right for You? — Decision framework, prerequisites, and partition strategy
- Part 2: Architecting for Eventual Consistency in EDA — Consistency patterns, Sagas, orchestration vs choreography, and multi-topic correlation
- Part 3: Schema Evolution, Idempotency, and Guaranteed Delivery — Schema registries, idempotency patterns, and transactional outbox
- Part 4: The Operational Reality of Event-Driven Architecture — Monitoring, costs, anti-patterns, and the complete implementation checklist
TL;DR for the entire series: Event-driven architecture demands operational discipline over tooling sophistication. Success requires three foundations: partition strategy that determines ordering and parallelism, schema registries that enforce contract evolution, and consumer idempotency that handles duplicate messages. EDA transforms simple three-component systems into complex fifteen-component distributed architectures—understand the operational cost before committing.
Skip to what you need:
- Already sold on EDA? Jump to Prerequisites
- Need to size partitions? Go to Partition Strategy
- Want the decision framework? Start with When EDA Is the Wrong Choice
When EDA Is the Wrong Choice
Event-driven architecture solves specific problems. But most teams adopting it never stop to understand what it actually involves. They don’t assess what needs to be in place before the first event is published. They don’t examine the operational foundations their system requires, the debugging capabilities their team needs, or the governance processes that prevent production disasters. They commit to the architecture and discover the demands later—usually during an incident.
Before you make that commitment, understand what EDA actually demands and whether your problems justify the cost.
Use EDA When
You need to decouple services with independent scaling requirements
Your payment processing service shouldn’t scale identically to your notification service. Event-driven architecture lets the payment service publish payment.processed events and continue operating even when the notification service falls behind processing confirmation emails.
Multiple downstream systems must react to the same business events
When an order is placed, inventory needs to be reserved, payment needs to be charged, shipping needs to be initiated, analytics needs to be updated, and fraud detection needs to score the transaction. With event-driven architecture, the order service publishes order.placed once. Each downstream system consumes independently.
You require audit trails and the ability to replay historical events
Financial systems, healthcare records, and compliance-critical applications need complete event history. Event streams provide immutable append-only logs where every state change is recorded and replayable years later.
You are building asynchronous workflows that can tolerate processing latency
Background processing, batch operations, data pipeline transformations, and long-running business processes don’t need synchronous confirmation. Users submit work and receive notifications when complete. Event-driven architecture enables these patterns naturally.
You need resilience where downstream failures should not impact upstream operations
Your order creation shouldn’t fail because the recommendation engine is down. With event-driven architecture, the order service publishes events regardless of downstream consumer health. Services fail independently without cascading failures.
Avoid EDA When
Your domain is naturally synchronous and users expect immediate feedback
Checkout requires immediate payment confirmation. Login requires immediate authentication response. Real-time multiplayer games require sub-100ms updates. Event-driven architecture adds latency that violates user expectations in these scenarios.
Strong consistency is a hard requirement you cannot compromise on
Bank account balances must be immediately consistent across withdrawals and deposits. Inventory must decrement atomically when items are purchased. Seat reservations must block concurrent bookings. Event-driven architecture chooses eventual consistency. If your domain cannot accept that trade-off, don’t use EDA.
Your team lacks operational maturity for distributed system debugging
Debugging event-driven systems requires correlating events across multiple topics, understanding causality in asynchronous flows, and tracing execution paths that span service boundaries. If your team struggles with basic microservice debugging, event-driven architecture will overwhelm them.
You have simple CRUD operations without complex integration needs
An internal admin dashboard with database reads and writes doesn’t need event-driven architecture. A content management system for a small team doesn’t need event-driven architecture. The operational overhead exceeds the benefit.
The system is small enough that a monolith or simple request-response suffices
Monoliths are underrated. A well-designed modular monolith with a database and an API layer handles millions of requests per day. Event-driven architecture is not a prerequisite for scale. It’s a solution to specific decoupling and resilience problems.
Red Flags That Indicate Premature Adoption
“We want to be modern” without articulating specific problems EDA solves
Modern architecture doesn’t mean event-driven architecture. It means architecture that solves your actual problems. If you can’t explain which specific problems EDA solves, you’re chasing trends.
“We might need it later” when current requirements do not justify the complexity
You will not need it later if you don’t need it now. Over-engineering for theoretical future requirements is how you create systems no one understands and everyone fears touching.
“All the successful companies use it” without understanding their scale or constraints
Netflix uses event-driven architecture because they process billions of events daily across hundreds of microservices. You are not Netflix. Their constraints are not your constraints. Copy solutions, not success stories.
The Decision Framework
Can you clearly explain which specific problems EDA solves for your system?
If the answer is vague or aspirational, you’re not ready. A well-designed request-response system is always better than a poorly understood event-driven one.
Prerequisites for EDA Success
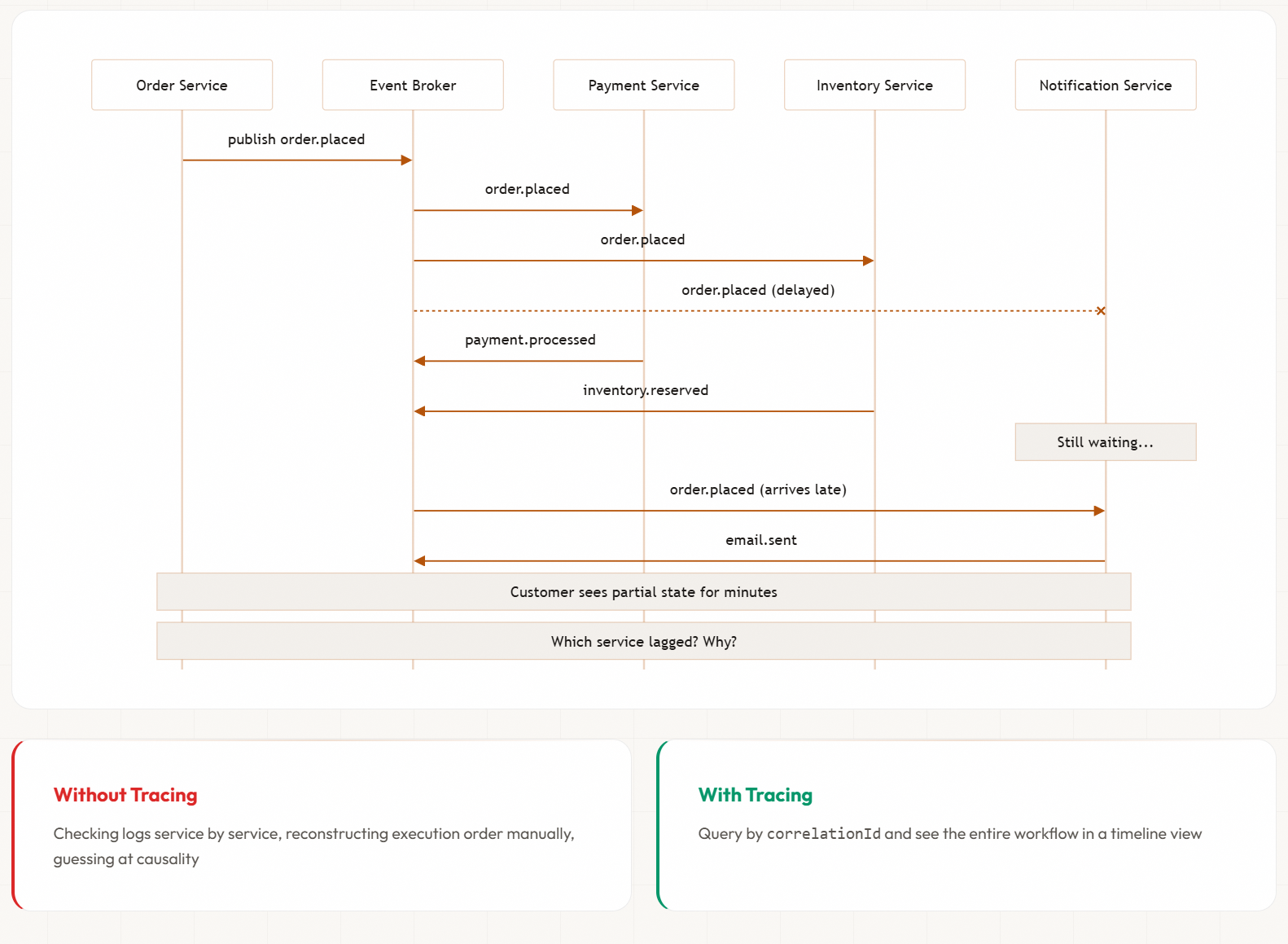
Before you write a single line of event-driven code, ask whether your team can trace a single business transaction across multiple services and topics.
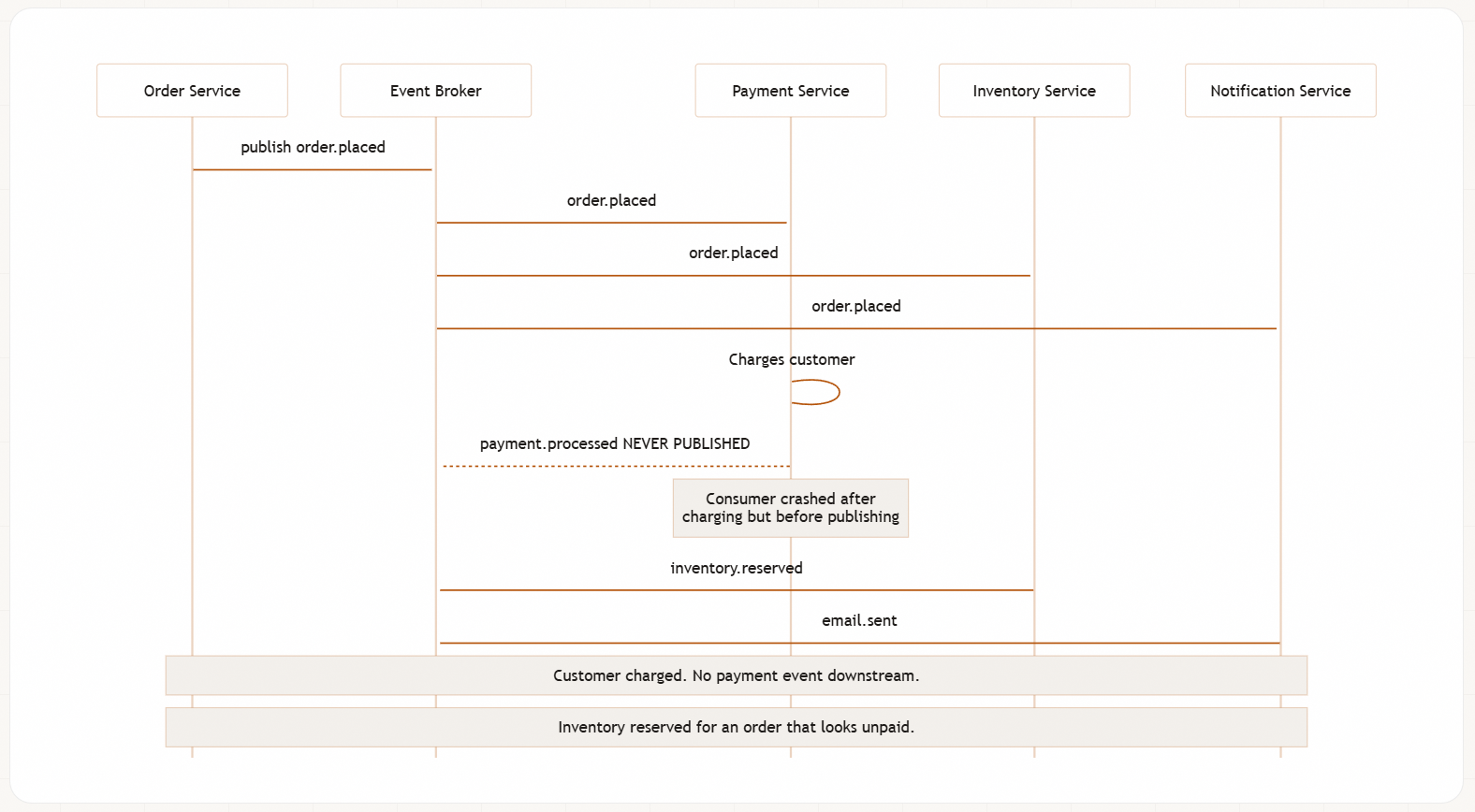
Consider an order workflow where events flow across payment, inventory, and notification services. An event arrives late at one consumer and the customer sees partial state for minutes. Or worse: the payment service charges the customer, then crashes before publishing payment.processed. The event chain breaks silently. Every service reports healthy. No errors in logs. The customer is charged but the order looks unpaid. You only find out when the customer calls support.
Without distributed tracing that links a correlationId across every event in the chain, you’re checking logs service by service, reconstructing execution order manually, and guessing at causality. With proper observability infrastructure, you query by correlationId and see the entire workflow in a timeline view.
If your team doesn’t have centralised logging with structured event metadata and distributed tracing across service boundaries, you cannot debug event-driven systems effectively. Build this first.
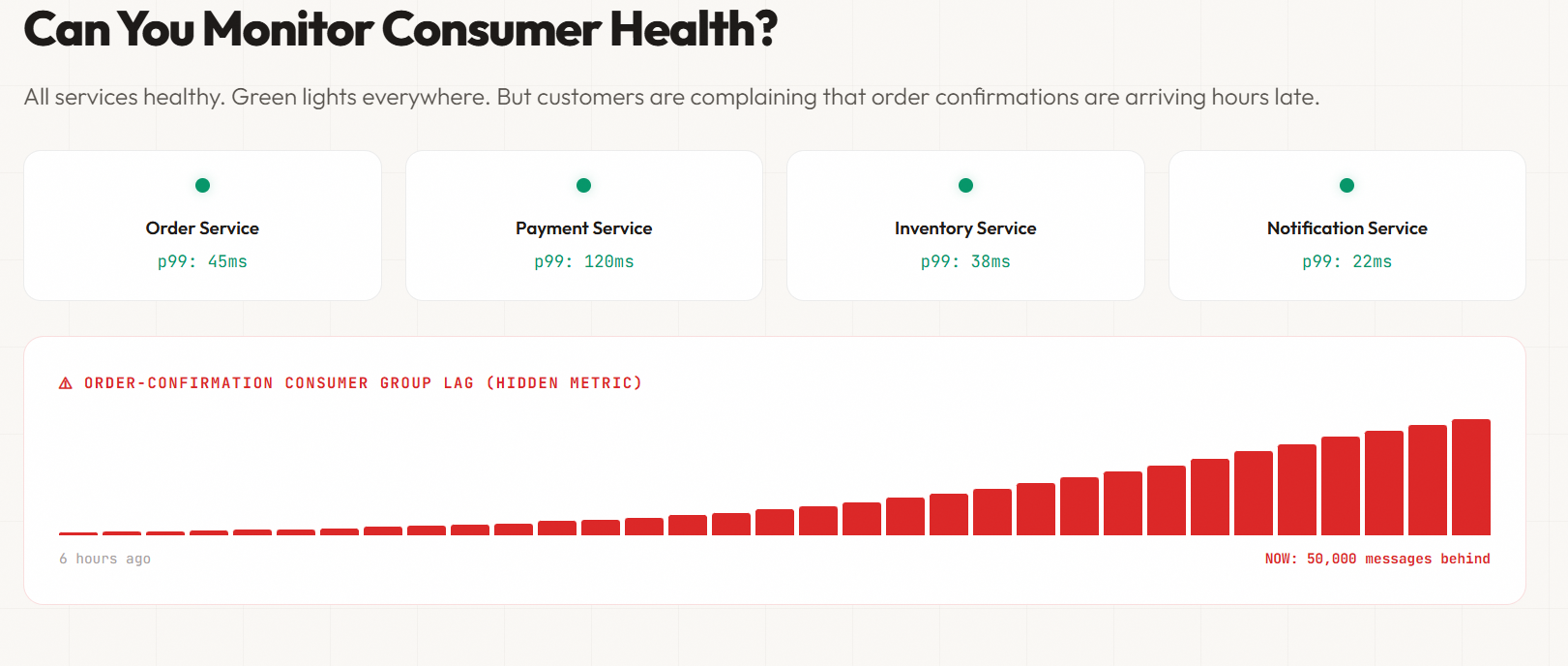
Observability Scenario: Can You Monitor Consumer Health?
Your monitoring dashboard shows all services are healthy. Green lights everywhere. But customers are complaining that order confirmations are arriving hours late.
You check consumer lag metrics. The order-confirmation consumer group is 50,000 messages behind and climbing. Events are being processed, just too slowly. You need to scale consumers or optimise processing logic immediately.
Without consumer lag monitoring, you discover this problem when customers complain, not when the lag starts climbing. Consumer lag is your canary in event-driven systems. If you’re not monitoring it partition-by-partition, per consumer group, you’re flying blind.
Schema Governance Scenario: Can You Prevent Breaking Changes?
A developer changes the userId field from a string to an integer. The change looks clean in code review. Tests pass. The code deploys.
Within 10 minutes, six consumer groups crash with deserialisation errors. Events back up. Pages fire. The developer rolls back immediately.
But 10 minutes of production traffic published thousands of malformed events. They sit in dead letter queues, unprocessable. Downstream systems have data gaps. The team spends two days writing custom recovery scripts.
A schema registry with compatibility validation in your CI pipeline would have caught this before code review started. The registry would reject the schema change: “Changing field type is a breaking change.” The developer would add customerId as a new optional field instead, allowing gradual migration.
If you don’t have schema governance infrastructure, you will discover schema incompatibilities in production.

userId from string to integer. Tests pass (missing contract/schema tests). It deploys. Within 10 minutes, six consumer groups crashOperational Overhead Scenario: Are Stakeholders Ready?
Your engineering manager approves the event-driven architecture proposal. You start building.
Six months later, you’re running Kafka clusters, schema registries, Database with CDC pipelines, three new Lambda functions, a WebSocket API and CloudWatch dashboards monitoring consumer lag across twelve consumer groups.
Your original synchronous system had three components. Your event-driven system has fifteen. Your infrastructure costs doubled. Your debugging complexity tripled.
The engineering manager asks: “Why is this taking so long? Why is it so complex?”
Because you transformed request-response into distributed choreography. This is the operational reality of event-driven architecture. If stakeholders aren’t prepared for this transformation, you’ll face constant pressure to “simplify” architecture that cannot be simplified without removing the benefits EDA provides.
Have this conversation before you commit. Make the trade-offs explicit.

EDA Readiness Checklist
Before adopting event-driven architecture, verify your organisation has these foundations:
- [ ] Centralised logging with correlation IDs — You can trace a single business transaction across all service boundaries
- [ ] Distributed tracing infrastructure — OpenTelemetry, Jaeger, or equivalent instrumentation is operational
- [ ] Schema versioning strategy documented — You’ve decided on backward, forward, or full compatibility and how to enforce it
- [ ] Team comfortable debugging across service boundaries — Your team has successfully debugged multi-service issues before
- [ ] Stakeholders understand 3→15 component transformation — Engineering leadership knows this adds operational complexity
- [ ] Schema registry operational or planned — Infrastructure for centralised schema management exists
- [ ] Consumer lag monitoring capability — You can track lag per partition, per consumer group
- [ ] Idempotency patterns understood — Your team knows how to handle duplicate message processing
- [ ] Dead letter queue strategy defined — You know what happens when messages fail processing
- [ ] On-call processes for distributed failures — You’ve documented how to respond to EDA incidents
If more than three of these boxes are unchecked, focus on establishing foundations before adopting EDA. Premature adoption without operational maturity leads to production incidents, team burnout, and architectural failure.
Strategy First, Not Technology
The biggest risk in adopting event-driven architecture is not technical complexity. It’s overconfidence.
Avoid the Big Bang
Trying to convert an existing system to event-driven overnight is a reliable way to fail. Incremental adoption matters.
If you’re introducing EDA into an existing system, apply the strangler pattern: identify a single integration point, replace it with event-driven communication, monitor the impact, learn from operational challenges, and expand incrementally. Large-scale rewrites almost always introduce more risk than value.
Start with non-critical workflows. Use event-driven architecture for background notifications or analytics pipelines where failures have limited user impact. Learn how your team debugs distributed flows, how your monitoring detects consumer lag, and how your schema governance prevents breaking changes.
Once operational confidence builds, expand to critical paths. Not before.
Event Sourcing Reality Check
Do not reach for event sourcing by default.
Event sourcing is a specific and powerful pattern within EDA. It enables full auditability, state rebuilds through replay, and secondary use cases like analytics without redesign. But it comes with structural constraints that many teams underestimate.
The complexity multiplier: Event sourcing is typically paired with CQRS (Command Query Responsibility Segregation) because querying event logs directly is impractical for most use cases. This combination introduces operational and conceptual complexity at every layer:
- Projection management: You must maintain read models derived from event streams. When projections fail or drift, you rebuild from event history. This requires versioned projection logic and migration strategies.
- Event schema evolution across immutable history: You cannot change historical events. Every schema change must handle events published with previous schemas. Your code must deserialise and process five schema versions simultaneously.
- Debugging through replay: When a bug corrupts projections, you replay events to rebuild state. If the replay logic has bugs, you corrupt state again. Debugging becomes multi-dimensional.
- Snapshot coordination: To avoid replaying millions of events on every restart, you create snapshots. Now you manage snapshot versioning, snapshot storage, and snapshot invalidation strategies.
The operational shift teams underestimate:
Consider a bulk operation: reclassifying a carrier across 50,000 shipments. In a traditional system, that’s a single SQL statement. Done in seconds.
With event sourcing, you’re publishing 50,000 Shipment-Carrier-Updated events and rebuilding projections across your read models. This isn’t catastrophic—modern event stores handle 50,000 events comfortably, and well-designed systems use batch command handlers, parallel projection rebuilds, or pragmatic direct read-model updates for administrative operations. But the point is that you need to have planned for this. Teams that treat bulk operations as an afterthought discover at the worst possible moment that their event-sourced system has no efficient path for administrative corrections.
The challenge isn’t that event sourcing can’t handle these scenarios. It’s that every operation you’d take for granted in a traditional system requires deliberate design in an event-sourced one.
The pressure test: Before committing to event sourcing, answer these questions explicitly:
- Can your business processes live with immutable event history where corrections require compensating events, not deletions?
- Have you designed for bulk operations and administrative corrections, not just happy-path event flows?
- Are stakeholders prepared for CQRS complexity where writes and reads use fundamentally different models?
- Do you have operational expertise to manage projection rebuilds, event schema evolution across years of history, and snapshot strategies?
Event sourcing should be a deliberate architectural decision based on specific requirements, not the starting point because it sounds sophisticated.
💡 When Event Sourcing Actually Works
This section warns against event sourcing, but it’s powerful for specific use cases: audit-critical systems (banking, healthcare), systems requiring time-travel debugging, or domains where events truly are the source of truth (trading, gaming).
The warning is: don’t start with event sourcing—evolve to it when you have a clear use case and operational maturity to manage its complexity.
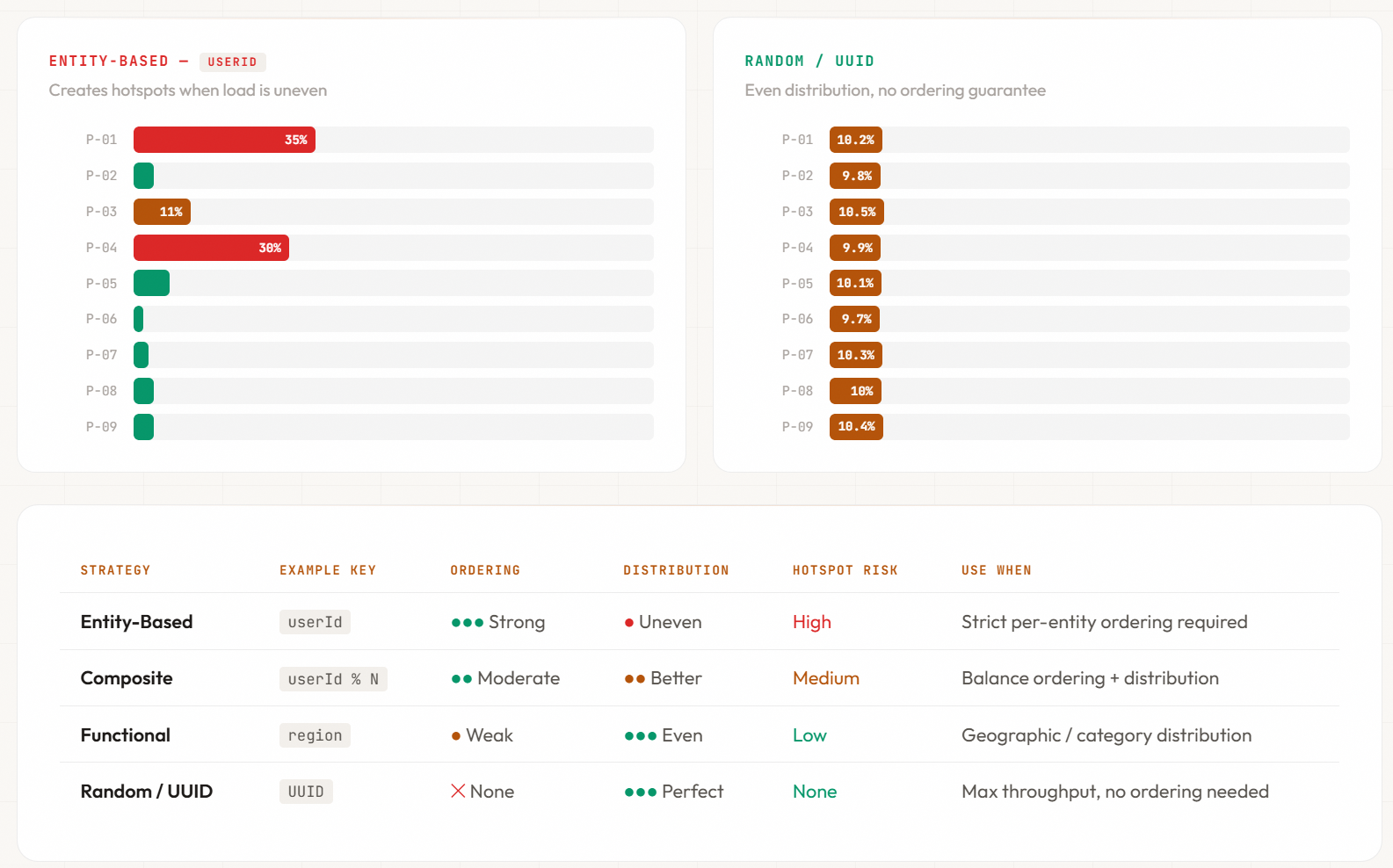
Partition Strategy Determines Your Constraints
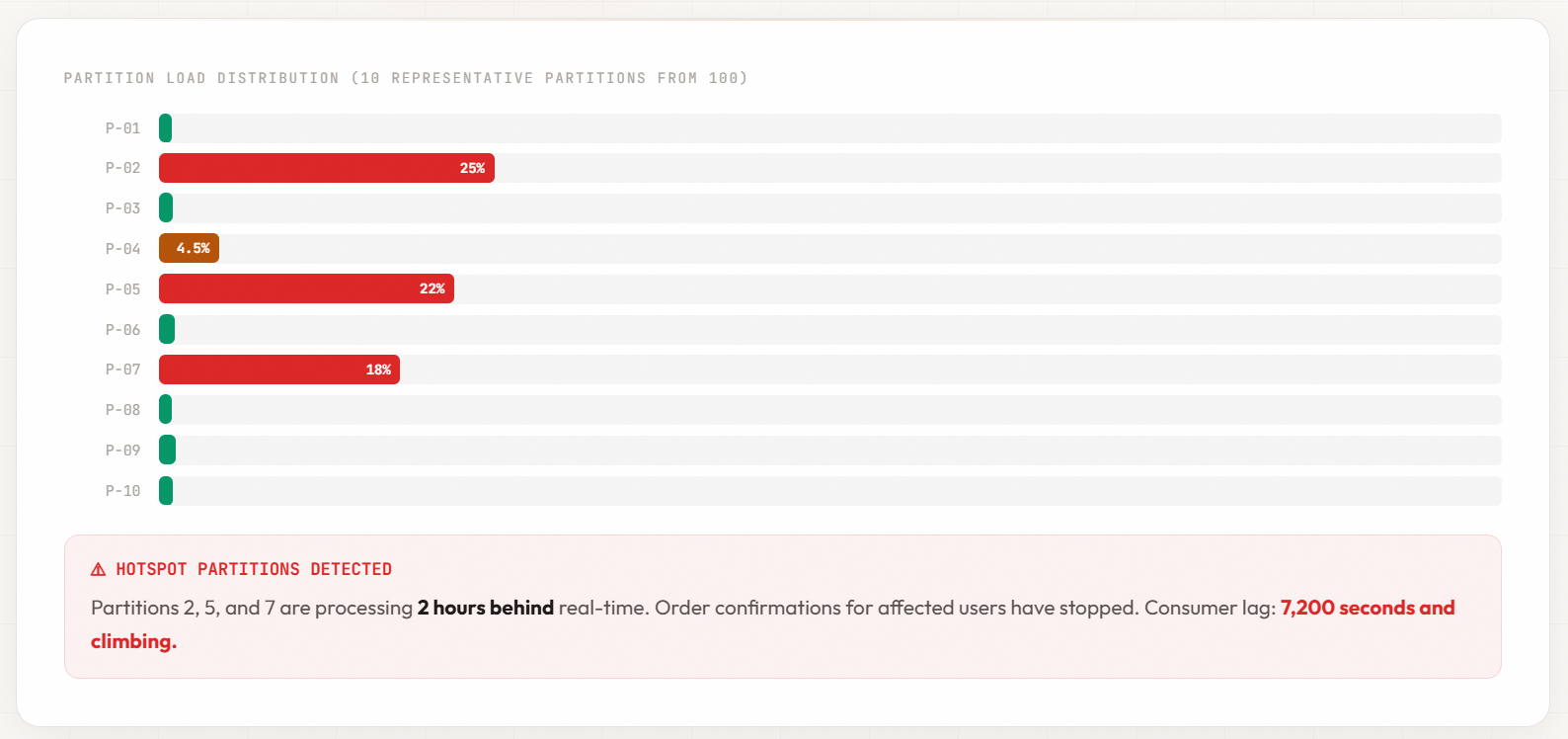
This is a pattern that plays out repeatedly: a team partitions by customer ID because it guarantees per-customer ordering. It works in testing. It works in production—until traffic growth exposes the distribution problem. In most B2B systems, 20% of customers generate 80% of the events. Those high-activity customers hash to a handful of partitions, creating hotspots that bring consumer groups to a crawl while the remaining partitions sit idle. Consumer lag climbs on the hot partitions. Processing stalls. And the system looks healthy everywhere except where it matters.
The partition key is the most consequential design decision you’ll make in EDA. You can’t easily change it. And it determines three things you care about deeply: ordering guarantees, parallelism limits, and where your system breaks under load.
Partition Key Trade-offs
Your partition key choice involves fundamental trade-offs. There’s no perfect answer—only informed decisions about which constraints you can accept.
Entity-Based Partitioning
Strategy: Partition by entity identifier (user ID, order ID, account ID)
# Entity-based: strong ordering per user
partition_key = f"user:{user_id}"
Guarantees: All events for a single user flow to the same partition in order. This enables reconstructing user state chronologically without complex correlation logic.
Risk: Uneven key distribution creates hotspot partitions. If 10% of your users generate 90% of events, those users’ partitions become bottlenecks. One high-activity user can monopolise a partition while other partitions sit idle.
Use when: Ordering per entity is a hard requirement (banking transactions, user session tracking, audit trails) and you have relatively even distribution of activity across entities.
Composite Keys for Better Distribution
Strategy: Combine entity identifier with a distribution hash
# Composite: better distribution while preserving some entity grouping
partition_key = f"{user_id % 100}:{user_id}"
Guarantees: Events for a single user are distributed across fewer partitions (user ID modulo 100 creates 100 buckets). This spreads high-activity users across multiple partitions while maintaining partial ordering.
Risk: You lose strict per-user ordering. Events from the same user may arrive at different consumers out of order. Consumers must handle reordering if strict chronological ordering matters.
Use when: You need better distribution than pure entity-based keys but can tolerate some out-of-order processing with consumer-side reordering logic.
Functional Partitioning
Strategy: Partition by functional attribute (region, product category, tenant)
# Functional: partition by region
partition_key = f"region:{region_code}"
Guarantees: All events for a region flow to the same partition. This enables regional processing isolation and geographic failover strategies.
Risk: Distribution depends on functional attribute cardinality. If you have 5 regions and 100 partitions, 95 partitions sit mostly idle. If one region generates 80% of traffic, that partition becomes a bottleneck.
Use when: Your domain naturally partitions by functional boundaries with relatively even distribution (multi-tenant SaaS, geographic regions with balanced load).
Random Partitioning
Strategy: Random or round-robin distribution
# Random: maximum throughput, zero ordering
partition_key = str(uuid.uuid4())
Guarantees: Perfect load distribution. No hotspots. Maximum parallelism.
Risk: Zero ordering guarantees. Events arrive in arbitrary order. Consumers cannot rely on chronological processing. Correlation across events requires external state management.
Use when: You don’t need ordering, you prioritise throughput above all else, and your domain tolerates out-of-order processing (clickstream analytics, log aggregation, metrics collection).
Partition Count as Your Parallelism Ceiling
You cannot run more consumer instances than you have partitions.
With 10 partitions, you can run 10 consumers maximum. The 11th consumer sits idle. With 100 partitions, you can scale to 100 consumers.
More partitions enable greater consumer parallelism but introduce operational overhead:
- Rebalancing costs: When a consumer joins or leaves, Kafka reassigns partitions. With 1000 partitions, rebalancing takes longer and creates temporary processing pauses.
- Metadata overhead: Each partition requires metadata tracking. Thousands of partitions increase broker memory usage and coordination complexity.
- File handle consumption: Each partition on disk consumes file handles. Too many partitions can exhaust OS limits.
Start conservatively. Increasing partition counts later is possible but operationally disruptive. You create a new topic with more partitions, run dual-publishing to both topics during migration, migrate consumers to the new topic, backfill historical data if needed, and eventually decommission the old topic.
Decreasing partition counts requires topic recreation and data migration with downtime or complex dual-publishing strategies.
🔧 Partition Count Sizing Formula
Start with:
partitions = (target_throughput_MB/s ÷ partition_throughput_MB/s) × 1.5Example: 100 MB/s target throughput, 10 MB/s per partition → 15 partitions
Add 50% buffer for growth. Monitor actual consumer lag and partition-level throughput. Adjust based on real metrics, not theoretical calculations.
Monitor Partition-Level Metrics, Not Just Topic-Level
Uneven key distribution creates hotspot partitions that become systemic bottlenecks.
Monitor lag per partition, not just per topic. If partition 42 consistently lags behind partitions 0-99, your partitioning strategy is creating a bottleneck.
# Monitor per-partition lag
for partition in topic_partitions:
lag = latest_offset[partition] - committed_offset[partition]
if lag > threshold:
alert(f"Partition {partition} lag: {lag} messages")
Graph partition-level throughput. If one partition processes 100K events/sec while others process 10K events/sec, you have a hotspot.
When you detect hotspots, you have three options:
- Optimise consumer processing for the bottleneck partition specifically
- Revise partition key strategy to distribute load more evenly (requires topic migration)
- Accept the bottleneck if it affects a small percentage of traffic and mitigations are in place
The worst option is ignoring partition-level metrics and discovering hotspots during Black Friday.
Decision Framework for Partition Strategy
Use entity-based keys when:
- Ordering per entity is a hard requirement (financial transactions, user sessions)
- Entity activity distribution is relatively even
- You can monitor for hotspots and have mitigation strategies
Use composite keys when:
- You need partial entity grouping with better distribution
- Consumers can handle some out-of-order processing
- High-activity entities create hotspots with pure entity-based keys
Use functional keys when:
- Your domain naturally partitions by stable attributes (region, tenant)
- Functional attributes have balanced cardinality and distribution
- You need processing isolation by functional boundary
Use random keys when:
- Ordering doesn’t matter for your use case
- Maximum throughput is the priority
- Clickstream, logs, metrics, or other order-independent data
The critical principle: Define your partitioning strategy before your first producer goes live. Document the reasoning. Make the trade-offs explicit to your team. Monitor partition-level metrics continuously. Plan for migration if you discover your initial strategy was wrong.
⚠️ Partition Strategy Anxiety
This section creates anxiety about partition strategy, but for 80% of use cases, simple round-robin or random partitioning works fine. Start simple. Monitor partition-level lag. Optimise when you have actual hotspot metrics—not theoretical concerns.
Modern Kafka supports partition expansion (though it requires care). Cloud platforms like EventBridge and Pub/Sub abstract partitions entirely. Don’t let partition strategy paralysis prevent you from shipping.
Closing: You’ve Decided. Now What?
You’ve decided event-driven architecture fits your specific problems. You’ve verified prerequisites are in place. You’ve chosen your partition strategy deliberately, understanding the trade-offs between ordering guarantees and distribution.
Now the next challenge emerges: managing eventual consistency.
Unlike partition strategy—which you can plan before your first producer goes live—eventual consistency reveals itself through business processes that span multiple services. Getting this wrong doesn’t just cause technical failures; it causes business logic failures that corrupt state and violate user expectations.
A customer places an order. Inventory is reserved. Payment is charged. But shipment creation fails. What happens now? Do you refund automatically? Alert support? Show the customer a half-completed order? These aren’t edge cases—they’re guaranteed scenarios in distributed systems.
Part 2 explores how to architect for eventual consistency deliberately—not discover it during incidents. We’ll cover:
- Sagas for coordinating multi-step workflows with compensating actions
- The controversial callback topic pattern and when it violates EDA principles
- Multi-topic correlation and the hidden complexity of fan-in operations
- Orchestration vs choreography: when to use each and why hybrid approaches often work best
The teams that succeed with event-driven architecture design for these failures upfront with disciplined patterns. The teams that struggle retrofit compensation logic during 3 AM incidents.
Next in this series: Part 2: Architecting for Eventual Consistency in EDA
Series navigation:
- Part 1: Is Event-Driven Architecture Right for You? (you are here)
- Part 2: Architecting for Eventual Consistency in EDA
- Part 3: Schema Evolution, Idempotency, and Guaranteed Delivery
- Part 4: The Operational Reality of Event-Driven Architecture
This series is based on years of production experience running event-driven systems at scale, from streaming platforms handling billions of events to CDC pipelines where data loss is unacceptable. The lessons are battle-tested. The failures are real. The guidance prioritises operational reality over architectural idealism.