This is Part 2 of a 4-part series on what event-driven architecture actually demands. Part 1 covered when EDA is the right choice, prerequisites for success, and partition strategy fundamentals. This part explores how to architect for eventual consistency deliberately.
After deciding EDA fits your needs and establishing your partition strategy, the next challenge emerges: managing eventual consistency. Unlike partition strategy, which you can plan before your first producer goes live, eventual consistency reveals itself through business processes that span multiple services.
Choosing event-driven architecture means choosing eventual consistency. The only question is how well you manage it.
Most teams discover eventual consistency the hard way. A customer places an order, payment succeeds, but inventory reservation fails. Now what? Do you refund automatically? Alert support? Show the customer a half-completed order? These aren’t edge cases; they’re guaranteed scenarios in distributed systems.
The teams that succeed with EDA design for these failures upfront with patterns like Sagas. The teams that struggle retrofit compensation logic during 3 AM incidents.
Here’s how to architect for eventual consistency deliberately.
TL;DR: Eventual consistency demands structured patterns, not wishful thinking. Sagas coordinate multi-step workflows with compensating actions. Commands and events are fundamentally different communication patterns — use commands (message queues) for orchestration within bounded contexts, domain events (event streams) for choreography across them. Multi-topic correlation requires deliberate strategies. The hybrid architecture — commands within, events across — isn’t a compromise; it’s how production systems should work.
This post covers five areas:
- Eventual Consistency Is Not Optional — Sagas, compensation logic, and the orchestration vs choreography choice
- The Callback Topic Debate — Why callback topics are really async RPC, the commands vs events distinction, and choosing the right infrastructure for each
- Fan-Out vs Fan-In Complexity — Why splitting streams is easy but joining them is hard, and what that means for your architecture
- Multi-Topic Correlation — Three concrete approaches (temporal datastores, stream processing, source aggregation) with production code
- Orchestration vs Choreography in Practice — The hybrid architecture: commands within bounded contexts, events across them
Eventual Consistency Is Not Optional
Consider a typical e-commerce order flow. A customer places an order. Your system must reserve inventory, charge payment, and create a shipment. Each step is handled by an independent service publishing events to separate topics.
What happens when payment fails after inventory is already reserved? What if shipment creation fails after payment succeeds? Without compensation logic, you have inconsistent state: inventory reserved but never shipped, payment charged with no order, or orders stuck in limbo waiting for manual intervention.
In synchronous systems, transactions provide atomicity. Either all steps succeed or all steps roll back. In event-driven systems, you cannot rely on distributed transactions. Instead, you must design compensation into your workflows from the start.
Introduction to Sagas
The Saga pattern provides a structured approach to multi-step business processes in distributed systems. A Saga represents a sequence of local transactions where each step can be compensated if a later step fails.
How Sagas work:
- Break the business process into discrete steps
- Each step completes a local transaction and publishes an event
- If any step fails, compensating transactions reverse previous steps semantically
- The workflow either completes fully or compensates fully
The order example as a Saga:
Step 1: Reserve inventory → Success → Event: inventory.reserved
Step 2: Charge payment → Success → Event: payment.processed
Step 3: Create shipment → FAILURE
Compensation:
Step 2 compensation: Refund payment → Event: payment.refunded
Step 1 compensation: Release inventory → Event: inventory.released
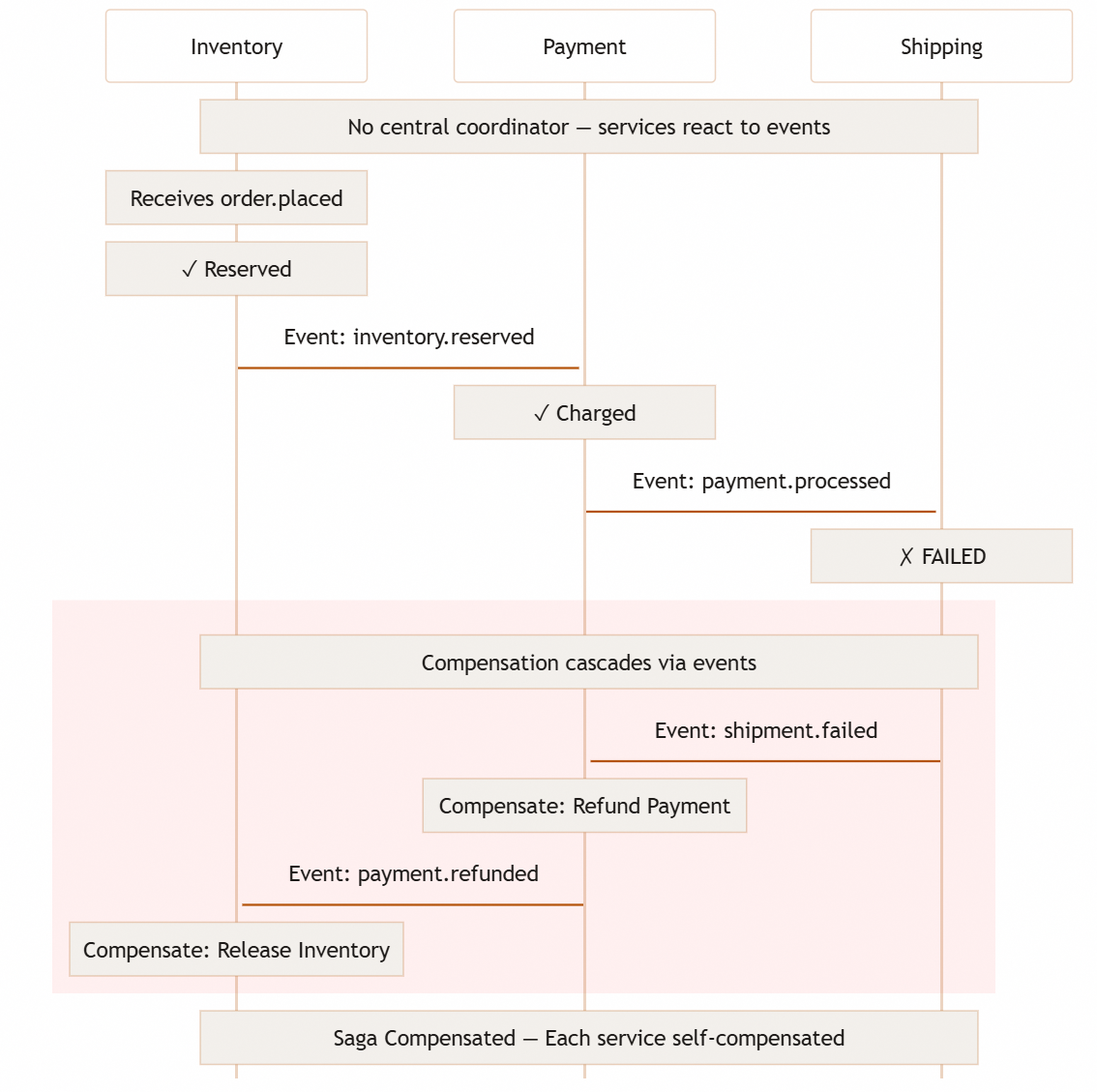
Each service maintains its own data and makes local decisions. When failures occur, compensating actions restore consistency. The customer sees a failed order with a refund rather than a half-completed order with no shipment.
Compensation is not rollback. The inventory was reserved, the payment was charged, and those actions happened. Compensation acknowledges this by publishing new events that semantically reverse previous actions. The event log shows the complete history: reservation, charge, failure, refund, release.
This historical record matters for audit, debugging, and business analytics. Unlike database rollbacks that erase history, Saga compensation preserves the full timeline of what occurred.
Orchestration vs. Choreography
Sagas can be implemented through orchestration or choreography. The choice determines visibility, control, and operational characteristics.
Orchestration uses a central coordinator that explicitly manages workflow steps. The orchestrator sends commands to services, receives results, and decides the next step or triggers compensation. The workflow is explicit in the orchestrator’s code. You can inspect a single service to understand the entire process.
Choreography distributes workflow logic across services. Each service listens for events, performs its work, and publishes events that trigger the next service. There is no central coordinator. The workflow emerges from service interactions. Understanding the complete process requires examining all participating services.
The trade-offs follow from this split.
Orchestration provides visibility and explicit control but creates a central coordination point. If the orchestrator fails, workflows stall. If the orchestrator becomes a bottleneck, it limits throughput. But debugging is straightforward: inspect orchestrator logs to see workflow state.
Choreography maximizes decoupling and eliminates central coordination points. Each service operates independently. Scaling is simpler. But debugging is harder: reconstructing workflow state requires correlating events across multiple services. Without distributed tracing, understanding what happened during failures becomes investigative work.
Most robust systems use both: orchestration within bounded contexts where visibility matters, choreography across them for maximum decoupling.
But understand what you lose without choreography: if every interaction is a central orchestrator sending commands and receiving responses, you’ve built asynchronous request-response, not event-driven architecture. The system works, but you’ve missed the architectural power that justifies EDA’s complexity. That power lies in domain events, and the infrastructure that supports them.
The Callback Topic Debate
Orchestration in event-driven systems forces a decision: how should processors communicate results back to orchestrators? The callback topic pattern is one common answer, pragmatic but architecturally revealing.
The Pattern
When an orchestrator needs async work performed, it publishes a request containing routing information:
{
"orderId": "ord-12345",
"action": "processPayment",
"amount": 99.99,
"callbackTopic": "order-orchestrator.callbacks",
"callbackReferenceId": "ord-12345-payment"
}
The processor completes the work and publishes the result to the specified callback topic. The orchestrator consumes only from its dedicated topic, correlating results by reference ID. This works. Teams ship quickly.
But it reveals something important about what you’re actually building.
This Is Async RPC, Not Event-Driven Architecture
When you encode callbackTopic and callbackReferenceId in a message, you’re specifying a return address and correlation identifier. This is request-response communication over event infrastructure.
The problems are structural:
- Topics become routing plumbing, not domain events.
order-orchestrator.callbacksreveals infrastructure, not your business domain. Runningkafka-topics --listshould show your business model, not orchestration wiring. - Events become non-reusable. The callback response contains a
referenceIdmeaningful only to one orchestrator. Analytics, fraud detection, and dashboards can’t use it. You lose the primary benefit of events: publish once, consume many times. - Governance scales multiplicatively. N orchestrators across M environments = NM callback topics, each needing permissions, retention policies, monitoring, and lifecycle management. Without strict governance, these become organizational debt nobody owns and nobody dares delete.
- It masks what you’re building. Calling async RPC “event-driven” obscures your actual architecture. One pattern broadcasts business facts. The other coordinates point-to-point work. They need different tools.
The Key Insight: Commands vs Events
The callback debate resolves when you recognize two fundamentally different communication patterns coexisting in every event-driven system:
Commands are point-to-point instructions: “Process this payment.” “Reserve this inventory.” They have a specific recipient and expect a result. They are message-driven: direct, intentional, targeted.
Events are broadcast business facts: “Payment was processed.” “Inventory was reserved.” They describe what happened in the domain. The publisher doesn’t know or care who listens. They are event-driven: decoupled, discoverable, reusable. Any downstream consumer can start subscribing at any time: analytics today, fraud detection next month, a recommendation engine next quarter. The publishing service never changes. This plug-and-play extensibility is the architectural power that justifies the operational cost of eventual consistency.
This extensibility is made possible by event streams: immutable, append-only logs with configurable retention. Unlike message queues where messages are consumed and deleted, events on Kafka, Kinesis, or EventBridge persist. Multiple consumer groups read the same stream independently, at their own pace, from any offset. One consumer processes events in real-time while another replays the last 30 days to bootstrap a new analytics pipeline. The stream doesn’t care. This retention and independent consumption model is what makes domain events fundamentally different from commands, and why event streams exist alongside message queues rather than replacing them.
The callback topic pattern fails because it uses event infrastructure for what are fundamentally commands and their responses. When your “events” have a return address and a reference ID, they aren’t events. They’re messages wearing event clothing. You’ve built async RPC on top of Kafka instead of leveraging what Kafka was designed for: durable, replayable, independently consumable domain events.
Practical Guidance
Once you distinguish commands from events, the choice of infrastructure follows:
| Communication | Nature | Infrastructure | Example |
|---|---|---|---|
| Commands | Point-to-point, expects response | Message queues (SQS, RabbitMQ) or direct invocation | “Process payment for order X” |
| Domain Events | Broadcast fact, no expected response | Event streams (Kafka, EventBridge) | “Payment processed for order X” |
These infrastructure categories exist for a reason. They are designed for fundamentally different consumption models:
Event streams (Kafka, Kinesis, EventBridge) are purpose-built for domain events. They are immutable append-only logs with configurable retention (days, weeks, or indefinitely). Multiple consumer groups read the same stream independently at their own pace. A real-time fraud detector and a nightly batch analytics job consume the same payment.processed topic without interfering with each other. New consumers replay from any offset to bootstrap their state. Events are never deleted by consumption. They expire by retention policy. This is what makes plug-and-play possible: the stream exists as a durable record of business facts, available to any consumer that needs them.
Message queues (SQS, RabbitMQ) are purpose-built for commands. Messages are consumed and acknowledged, then deleted. One message goes to one consumer (or one consumer group via competing consumers). There is no replay. Once consumed, the message is gone. No ability for a second consumer to independently process the same message. No retention for historical analysis. Queues excel at reliable point-to-point delivery with backpressure and retry semantics, which is exactly what orchestration commands need.
The mismatch works in one direction: you can use Kafka or Kinesis for commands when you need the fault tolerance, ordering guarantees, and replayability that event streams provide for your orchestration signals. But you cannot use queues for events because they lack the retention, replay, and independent multi-consumer model that domain events require. A queue fundamentally cannot support a new downstream service subscribing next month and processing the last 90 days of events to build its initial state.
Use both deliberately. Most production systems should. Orchestrate with commands within bounded contexts where visibility matters. Publish domain events across bounded contexts for independent consumption. This isn’t a compromise; it’s the architecturally sound approach. We’ll see this hybrid pattern in practice when we discuss orchestration vs choreography.
💡 Devil’s Advocate: Pragmatism vs. Purity
At extreme scale, consuming domain events requires filtering. An orchestrator processing 1,000 orders per hour must consume and filter 100,000 payment events to find the relevant ones. If callback topics serve a transitional purpose, acknowledge this is async RPC, document the trade-off, establish strict governance, and plan the migration path. The key: make it a deliberate choice, not accidental architecture.
Understanding Fan-Out vs Fan-In Complexity
The orchestration patterns discussed above reveal a fundamental architectural asymmetry in event-driven systems. Splitting one stream into many (fan-out) is straightforward. Joining many streams into one (fan-in) is complex.
Fan-Out is Easy
Fan-out takes a single source topic and produces multiple derived topics through content-based routing or filtering. The operation is stateless. Each destination is independent.
For example, route payment.processed events by status into domain-specific topics:

# Stateless content-based router
for event in consume('payment.processed'):
if event['status'] == 'SUCCESS':
publish('payment.succeeded', event)
elif event['status'] == 'FAILED':
publish('payment.failed', event)
if event['riskScore'] > THRESHOLD:
publish('payment.flagged', event)
Each destination topic is independent. If payment.flagged consumers lag during a fraud investigation spike, it doesn’t affect payment.succeeded processing. Failures are isolated. Scaling is simple: add more router instances.
Notice the topic names: payment.succeeded, payment.failed, payment.flagged all describe business facts. They follow the same domain naming principle from the callback debate — kafka-topics --list should reveal your business model, not infrastructure wiring.
Fan-In is Hard

Fan-in joins multiple source topics into one aggregated view. This requires state management, time windowing, lag coordination, and handling events that arrive at different rates or out of order.
The problem: correlate events from payment.processed, inventory.reserved, and shipment.created to build complete order status.
The challenges compound quickly. You need state management across all source topics, time windows to decide how long to wait for related events, and lag coordination when shipment.created runs 10 minutes behind payment.processed. Events might arrive out of order, and you have to decide when to declare a correlation incomplete if payment succeeds but shipment never arrives.
These problems don’t have simple solutions. Stream processing frameworks provide primitives for joins and windowing, but tuning them correctly requires deep understanding of your data characteristics and latency requirements.
Design your architecture to prefer fan-out over fan-in. Single source topics that get routed to multiple destinations scale better than multiple source topics that must be joined.
When fan-in is unavoidable (building customer journey views, reconstructing business transactions, correlating multi-service workflows), recognize the complexity and choose deliberate strategies.
Multi-Topic Correlation and Cross-Stream Ordering
Sometimes fan-in is not optional. Your system must correlate events from multiple topics to fulfill business requirements. Understanding your options prevents retrofitting correlation logic during production incidents.
The Problem Made Concrete
Your customer service dashboard shows complete customer journeys: every click, cart interaction, and purchase event, displayed in chronological order. This helps support agents understand customer behavior and resolve issues quickly.
The problem: clicks come from page.viewed (100 partitions), cart updates from cart.updated (50 partitions), and purchases from order.placed (30 partitions). Three independent services publish these events with different throughput rates and different lag characteristics.
How do you reconstruct an accurate timeline when events arrive out of order across three different topics?
Approach 1: Temporal Correlation Datastore
Store events from all three topics in a database with customer ID as the partition key and timestamp as the sort key. Query by customer ID and time range to reconstruct the journey.
DynamoDB implementation:
import boto3
from datetime import datetime
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('customer-events')
# Consumer writes events to DynamoDB
def store_event(topic, event):
table.put_item(Item={
'customerId': event['customerId'], # Partition key
'timestamp': int(event['timestamp']), # Sort key (milliseconds)
'eventType': event['type'],
'eventSource': topic,
'payload': event,
'ttl': int(datetime.now().timestamp()) + 86400 # Auto-expire after 24h
})
# Consumer for each topic
for event in consume('page.viewed'):
store_event('page.viewed', event)
for event in consume('cart.updated'):
store_event('cart.updated', event)
for event in consume('order.placed'):
store_event('order.placed', event)
# Query customer journey
def get_customer_journey(customer_id, start_time, end_time):
response = table.query(
KeyConditionExpression='customerId = :id AND #ts BETWEEN :start AND :end',
ExpressionAttributeNames={'#ts': 'timestamp'},
ExpressionAttributeValues={
':id': customer_id,
':start': int(start_time.timestamp() * 1000),
':end': int(end_time.timestamp() * 1000)
}
)
return sorted(response['Items'], key=lambda x: x['timestamp'])
Pros and cons:
Advantages:
- ✅ Works with any event source
- ✅ Approximate ordering acceptable for many use cases
- ✅ Simple consumer logic: write events, query later
- ✅ TTL handles cleanup automatically
Disadvantages:
- ❌ Database dependency (another failure point)
- ❌ Query latency (not real-time processing)
- ❌ Requires DynamoDB operational expertise
- ❌ Ordering based on event timestamps, not processing order
This approach works when you can tolerate query latency and approximate ordering. Dashboard queries happen infrequently compared to event volume, so database queries are acceptable.
Approach 2: Stream Processing for Joins
Stream processing frameworks like Kafka Streams, Flink, or Kinesis Analytics provide native support for joining multiple topics with time-windowed operations.
Kafka Streams example:
StreamsBuilder builder = new StreamsBuilder();
// Source streams
KStream<String, ClickEvent> clicks = builder.stream("page.viewed");
KStream<String, CartEvent> carts = builder.stream("cart.updated");
KStream<String, OrderEvent> orders = builder.stream("order.placed");
// Join clicks with carts within 5-minute window
KStream<String, CustomerActivity> clicksWithCarts = clicks.join(
carts,
(click, cart) -> new CustomerActivity(click, cart),
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(5)),
StreamJoined.with(Serdes.String(), clickSerde, cartSerde)
);
// Join result with orders within 10-minute window
KStream<String, CustomerJourney> fullJourney = clicksWithCarts.join(
orders,
(activity, order) -> new CustomerJourney(activity, order),
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofMinutes(10)),
StreamJoined.with(Serdes.String(), activitySerde, orderSerde)
);
// Publish joined result
fullJourney.to("customer.journey.enriched");
Pros and cons:
Advantages:
- ✅ Real-time stream processing
- ✅ Stays within event infrastructure
- ✅ Declarative join semantics
- ✅ State management handled by framework
Disadvantages:
- ❌ Complex windowing semantics to understand
- ❌ Lag in any source stream delays join output
- ❌ Steep learning curve for Kafka Streams
- ❌ Operational overhead of maintaining stream processing applications
- ❌ Window size tuning requires understanding data characteristics
Stream processing excels when you need real-time joins and your team has expertise with stream processing frameworks. The operational complexity is significant (state stores, checkpointing, rebalancing), but the capabilities are powerful.
Approach 3: Aggregate at Source
Often the most robust solution is to consolidate related events at the source before publishing them to the event stream. This moves complexity from consumers to producers but eliminates the correlation problem entirely.
Instead of separate events:
# Frontend publishes clicks
publish('page.viewed', {'userId': 'user-123', 'action': 'view_product', 'productId': 'prod-456'})
# Cart service publishes updates
publish('cart.updated', {'userId': 'user-123', 'action': 'add_item', 'productId': 'prod-456'})
# Order service publishes purchases
publish('order.placed', {'userId': 'user-123', 'orderId': 'ord-789', 'total': 99.99})
Publish consolidated activity events:
# Activity aggregator service
session_buffer = {} # In production: Redis with TTL
def record_activity(user_id, activity):
if user_id not in session_buffer:
session_buffer[user_id] = {
'sessionId': generate_session_id(),
'customerId': user_id,
'events': []
}
session_buffer[user_id]['events'].append({
'timestamp': datetime.utcnow().isoformat(),
'type': activity['type'],
'details': activity
})
# Publish aggregated session every 30 seconds or N events
if should_flush(session_buffer[user_id]):
publish('user.activity', session_buffer[user_id])
del session_buffer[user_id]
# Result: single topic with complete session context
publish('user.activity', {
'sessionId': 'sess-abc',
'customerId': 'user-123',
'events': [
{'timestamp': '2024-01-15T10:00:00Z', 'type': 'click', 'details': {...}},
{'timestamp': '2024-01-15T10:01:30Z', 'type': 'cart_add', 'details': {...}},
{'timestamp': '2024-01-15T10:05:00Z', 'type': 'order_placed', 'details': {...}}
]
})
Pros and cons:
Advantages:
- ✅ Eliminates correlation problem for consumers
- ✅ Events arrive with complete context
- ✅ No windowing or join complexity
- ✅ Single topic to consume from
Disadvantages:
- ❌ Producer complexity: must buffer and aggregate
- ❌ May delay events until aggregation window closes
- ❌ Requires coordination between producer services
- ❌ Buffering state management at producer
Source aggregation works when you control the producers and can coordinate aggregation logic. It moves complexity upstream but dramatically simplifies downstream consumers.
Decision Criteria
Choose the correlation strategy based on your operational capabilities and requirements:
| Approach | Use When | Avoid When |
|---|---|---|
| Temporal Datastore | Acceptable latency, approximate ordering OK, simple queries | Need real-time processing, strict ordering required |
| Stream Processing | Real-time requirements, team has stream processing expertise, need complex joins | Team lacks expertise, simple use case doesn’t justify complexity |
| Source Aggregation | Control producers, related events generated together, want to simplify consumers | Cannot coordinate producers, need granular event-level replay |
Start with the simplest approach that meets your requirements. Temporal datastores work for 80% of correlation use cases. Graduate to stream processing when you have specific real-time requirements and operational expertise.
⚠️ Devil’s Advocate: When Correlation Indicates Bad Design
If you need complex multi-topic correlation with strict ordering, ask: should these be separate events? The need for correlation often indicates services are too fine-grained or bounded contexts are poorly defined.
Before building correlation infrastructure, consider: why are related state changes published separately? An order placement that requires correlating payment events, inventory events, and shipment events across three topics might indicate these should be aggregated at the source, or that the services are decomposed incorrectly.
Sometimes fixing event design eliminates the correlation problem entirely. Refactoring bounded contexts may be cheaper than maintaining complex join infrastructure.
Orchestration vs Choreography in Practice
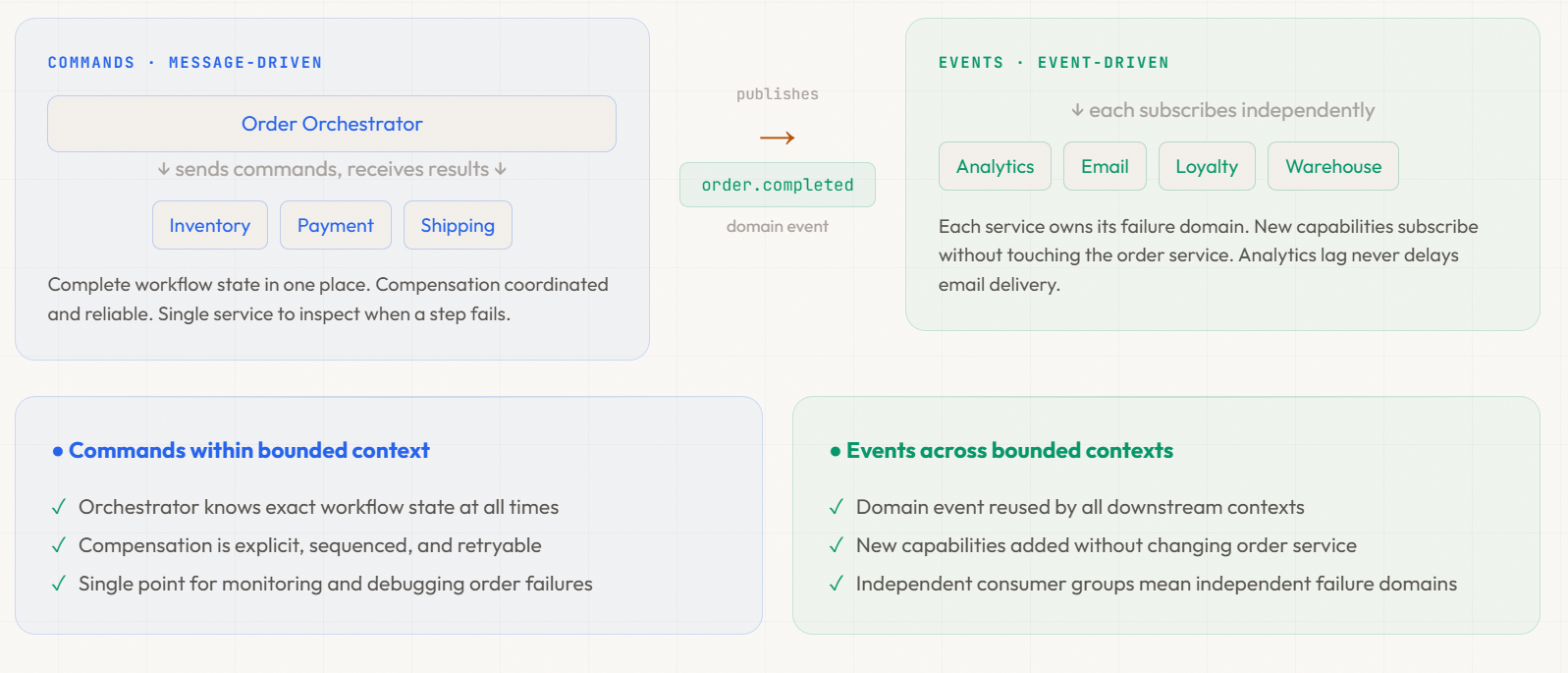
The commands vs events distinction from the callback debate reveals a deeper truth: orchestration and choreography are not binary choices. Real systems blend both deliberately: commands for internal coordination, domain events for cross-boundary communication.
The Hybrid Architecture: Commands Within, Events Across
Pure orchestration creates central coordination points. Pure choreography distributes logic across independently reacting services. Neither extreme is optimal for most systems.
Orchestration within bounded contexts uses commands: direct, point-to-point instructions with expected responses. The orchestrator sends “reserve inventory,” waits for the result, sends “charge payment,” waits, and coordinates compensation when failures occur. Commands flow through message queues or direct invocation, not event topics. This provides visibility and explicit control for critical workflows.
Choreography across bounded contexts uses domain events: broadcast business facts that any service can independently consume. When an order completes, order.completed is published as a domain event. Analytics, notifications, and loyalty all subscribe independently. These cross-domain reactions don’t need coordination; they’re independent capabilities reacting to business facts.
Here’s how it looks in an order processing system:
Within order context (commands, message-driven):
Order Orchestrator sends:
→ Command: "Reserve inventory" → Inventory responds ✓
→ Command: "Charge payment" → Payment responds ✓
→ Command: "Create shipment" → Shipping responds ✓
Orchestrator publishes domain event: order.completed
Across contexts (events, event-driven):
order.completed published to event stream →
→ Analytics subscribes (tracks revenue)
→ Email subscribes (sends confirmation)
→ Loyalty subscribes (awards points)
→ Warehouse subscribes (optimizes stock)
The orchestrator publishes a single domain event when its workflow completes. That event is the bridge between the command-driven internal world and the event-driven external world. Inside the boundary: full workflow visibility and coordinated compensation. Outside: maximum decoupling and independent consumption.
Isolation Principles
Whether using commands or events, isolation prevents cascading failures and enables independent scaling.
Each consuming capability should use its own consumer group. Analytics lag doesn’t affect email delivery; email failures don’t block loyalty point updates. Independent consumer groups mean independent failure domains.
Don’t share database pools, caches, or compute resources between critical and non-critical consumers. Order confirmation consumers get dedicated resources, analytics consumers share separate resources. Resource contention cannot cause business-critical processing to slow down.
Partition topics by bounded context, not organizational convenience. order events in one topic, payment events in another, inventory events in a third. This enables different retention policies, different scaling characteristics, and different access controls.
When to Use Each
Orchestration with commands fits when workflow visibility and control matter, when compensation logic is complex and must be coordinated, when you need explicit workflow state for monitoring and debugging, or when compliance requires audit trails. Financial transactions and critical business processes are the natural home.
Choreography with events fits when maximum decoupling matters more than visibility, when services belong to different bounded contexts or teams, when reactions are independent, or when you want to add new capabilities without changing existing services.
Watch for orchestration overuse: the central orchestrator becomes a bottleneck, orchestrator failure blocks all workflows, or the orchestrator coordinates across organizational boundaries. Watch for choreography overuse: you can’t reconstruct workflow state during incidents, business logic is scattered with no single source of truth, or implicit dependencies surface only during outages.
Choose based on coupling tolerance, visibility requirements, and operational capabilities. Document your choices. Make the trade-offs explicit to your team.
Closing: Build Patterns That Match Reality
Eventual consistency is not a limitation to minimize; it’s a reality to embrace with disciplined patterns. Sagas structure multi-step workflows with explicit compensation, and commands and events serve fundamentally different purposes: commands for orchestration within bounded contexts, domain events for choreography across them. Multi-topic correlation requires deliberate strategies that acknowledge operational complexity.
The most important lesson: not all communication in an event-driven system needs to be events. Commands are the right tool for point-to-point orchestration. Events are the right tool for broadcasting business facts. The hybrid architecture (commands within, events across) isn’t a compromise. It’s the pattern that matches how distributed systems actually work.
Choose patterns deliberately. Document trade-offs explicitly. Design for the system you have, not the textbook architecture you wish you had.
You now understand how to architect for eventual consistency. Sagas coordinate workflows, correlation strategies handle multi-topic scenarios, and orchestration and choreography blend strategically.
But even perfectly designed event flows fail without enforcement mechanisms: schema incompatibilities crash consumers, duplicates corrupt data, and database updates drift out of sync with event publishes.
Part 3 covers the non-negotiable technical foundations that prevent these failures: schema registries that block breaking changes in CI, idempotency patterns that handle duplicates correctly, and outbox patterns that guarantee delivery without distributed transactions. These mechanisms transform architectural plans into production-ready systems.
Continue to Part 3: Schema Evolution, Idempotency, and Guaranteed Delivery
Return to Part 1: Is Event-Driven Architecture Right for You?