
The answer is yes. You can combine the two.
Let’s look at two possible solutions.
FYI, I am basing the solution on a question I received on one of my videos https://youtu.be/U-U3bpljZd0.
The question was:

Possible Solution
Key architecture design decisions for my approach
Before we go through the two approaches, let me share my architectural design decisions.
- First, I will base my solution on it being hosted in AWS.
- I will use serverless services for the ease of delivery & scalability serverless provides.
- DyanmoDB will be the choice of Database because of its Change Data Capture (CDC) stream functionality in the form of DyanmoDB streams or DynamoDB Kenesis Data streams.
- Use AWS API Gateway to deploy, secure, monitor and proxy operations to the backend.
- Even though I won’t touch on it in this article, I would use central Lambda functions running within the API Gateway to authenticate and authorise the API operations.
- Kinesis Data Streams is my choice of middleware, which is an event stream.
- I’m not using a message queue or broker because I want long-term data retention and the ability to have multiple simultaneous consumers. And the ability to re-process.
And two fundamental principles to remember
- “Do Not Lose Events”.
- “Don’t do distributed transactions”.
Patterns on how to get the data into the Database
Database-First
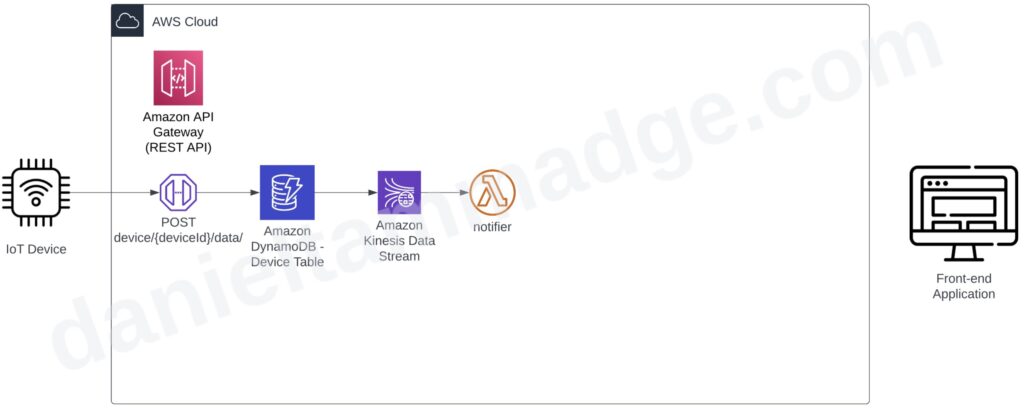
The first approach is what I call database-first when the API operation stores the request straight to a database table.
In this approach, I will use AWS API Gateway as a proxy for DyanmoDB by storing the data straight to DynamoDB without requiring a function to process the request and insert the record. If required you can have a service or a function to serve the API endpoint and perform the insert.
After successfully adding the record, the operation will notify that the operation was successful in the response back to the device.
Once the device data gets stored in DyanmoDB, the change gets pushed to the DynamoDB Kinesis Data Stream, and we will have a consuming lambda function to push the change to the connected client/s (the front-end app).
Event-First (or Storage-first)
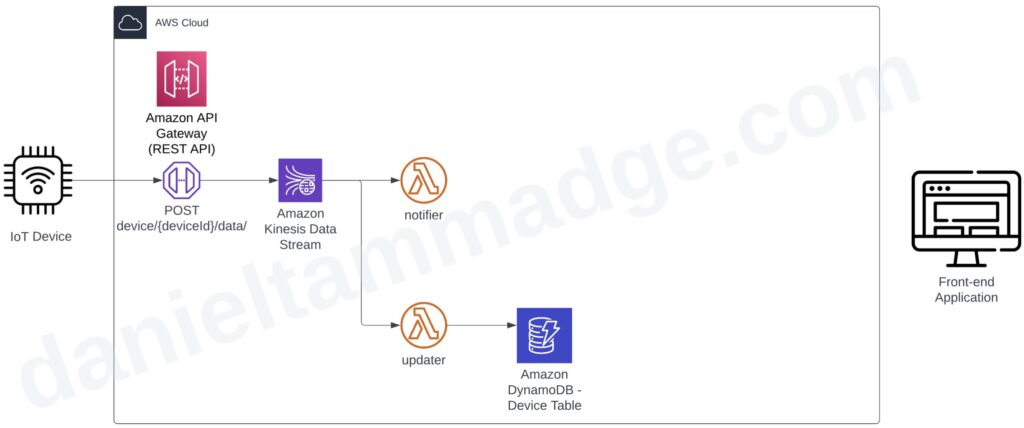
The second pattern is when a request to the API gets published straight to an event stream or message queue.
I call this pattern event-first. But I have heard this pattern, also referred to as storage-first. Now I know it’s referring to the fact it’s storing the request to a persistent middleware. However, it sounds wrong because when I hear storage, I think of a Database or a storage service like S3 or another service with long-term storage capability.
I know that kenisis does have a retention period of up to a year, but storage needs could exceed a year. Also, publishing to a message queue is short-term because messages get removed when they are processed.
If I were to call any pattern “storage-first”, it would be the first pattern when we stored straight to the database table. But the table could easily be an object storage service like AWS S3.
But back to the second pattern.
We can use the AWS API gateway to proxy the Kinesis Data Stream and write the device payloads record straight to the data stream. Again if required you can have a service or a function to serve the API endpoint and perform the write.
And we could have two lambda consumers that will process the events independently and at their own pace.
- One will store the payload in the dynamodb table.
- And the other could trigger the pushing of notifications to update the front-end app, which we will come to shortly.
Comparing Database-First & Event-First
Database-first processes data sequentially, while event-first allows parallel data processing as soon as the system receives it. As a result, database-first provides higher data consistency than event-first since data is stored in the Database before notifying the front-end app. Event-first, on the other hand, has a higher degree of eventual data consistency since notifying clients and storing data occur in parallel. Additionally, due to parallel processing, event-first reduces the time it takes for data to reach the front-end application, resulting in lower latency.
Alternative approach
You could instead add a lambda function to serve the API endpoint and perform two network calls; one to publish an event and another to store the request data in the Database. However, you would need to design a distributed transaction because what happens if one fails? How do you roll back? What if you can’t roll back?
Remember, the two principles don’t lose events and don’t do distributed transactions because distributed transactions are complex to get right.
https://youtu.be/91MR_Vec800 to understand more.
Pushing to clients
Now we need to push the events to the subscribed clients, which is the web application UI in this example. How would I do this?
Web Sockets
One approach would be to use Web Sockets from the Web application.
And we would set up web sockets by adding the following:
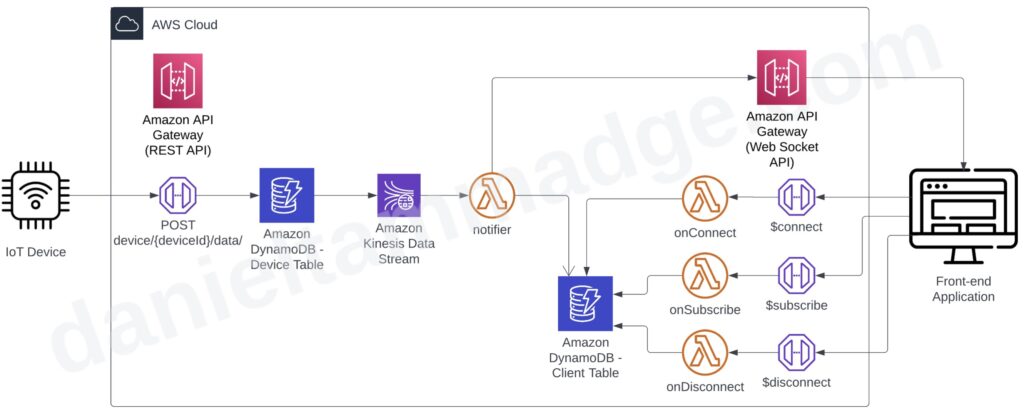
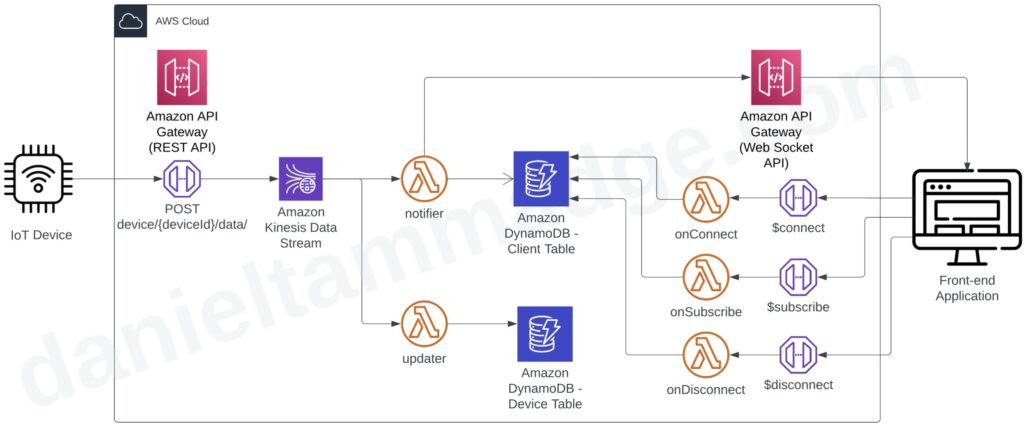
- Add a new Web socket API to the AWS API Gateway, and we will configure three routes $connect, $disconnected & subscribe.
- A DynamoDB table to hold the web socket connected client details
- A lambda function that serves the $connect route and stores the client details.
- A lambda function that serves the $disconnect route and removes the client details from the DyanmoDB table.
- And optionally, a Lambda function that serves the $subscribe route. The function could modify the client’s subscription settings in the DynamoDB table. This is if we want clients to specify what events to receive and for what.
When the front-end app starts up, the application will open the web socket connection. Then, the $connect lambda function will update the client connection table.
The application could subscribe to specific device notifications by calling the $subscribe route.
Now back to the backend.
The consuming lambda function will fetch the subscribed connected clients’ identifiers when an event gets pushed to the Kinesis Data Stream. Then the function will invoke POST HTTP requests to the web Socket API to invoke callback messages for each connected subscribed client using the connection identifier.
And the clients, the instances of the front-end UI, would update their UI dashboards as and when updates are received.
Ok, so we are using web sockets to push events to the UI. However, you may ask, “How do the clients fetch data on startup?”.
A solution is quite simple; you provide REST API endpoints which clients can consume to fetch data from the Database.
Or use GraphQL API because GraphQL supports pub/sub by default.
Conclusion
Finally, many solutions I know have
- Exposed a request-driven interface, and once an initial request is received or processed, publishes an event that will trigger downstream services using event-driven architecture.
- And Mixed request-driven and event-driven methods of communication between systems and services.
Don’t be fanatical or narrow-minded when it comes to designing systems. Use the range of tools in your toolbox, don’t use a hammer for a screw.
Stay tuned because I will be doing a follow-up describing how to incorporate other patterns and services.