Why loose Coupling and time-independent processing makes designing event-driven solutions complex
In request-driven services, if the processor of the request is unavailable, the caller would know straight away and be able to gracefully degrade and log that it cannot perform the operation.
Middleware (Loose Coupling)
However, once you put in place middleware, a queue or an event stream, and start using asynchronous event-driven communication. The publisher of the events is no longer coupled with the processor, the event consumer. The publisher won’t know if the processor is available or is not keeping up with throughput (consumer lag) because it will be able to publish events to the middleware regardless.
Time-independence / asynchronous processing
An event processor is not time-dependent. It will process events as and when it consumes them. We usually hope it is as quickly as possible, but if you have consumer lag or problems, this could be minutes or hours.
And when we introduce event-driven architecture into systems, we have to design for this additional complexity.
Going from a Synchronous request-driven system to an Asynchronous event-driven one. An Example
Hopefully, sharing a walkthrough of a solution where I took an existing synchronous request-driven solution and turned it into an asynchronous event-driven one will convey the complexities.
Issues with the existing Synchronous request-driven system
Ok, so we had an issue. Users were unhappy with an existing service because the service was slow and unable to accept the number of requests in busy periods. And I was tasked with fixing it.
However, we were unable at the time to improve the underlying issue. So we decided to change the service from synchronous to asynchronous and events to decouple the client and the processor so that the limit of the processor would not affect the client’s ability to send requests.
Not only did we make a lot of changes to the UI, to allow for the UX to be asynchronous, but the main impact was on the backend system.
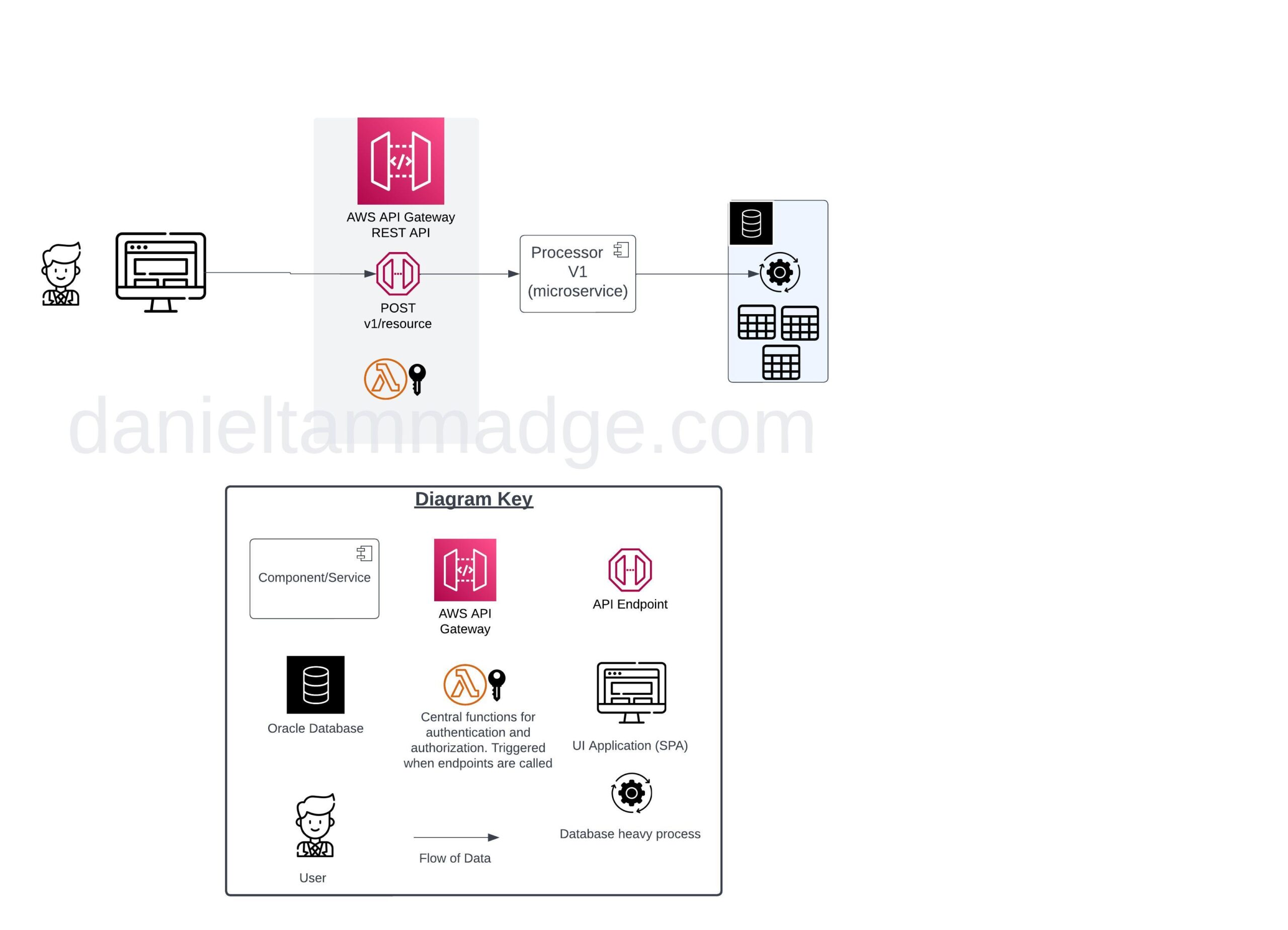
we went from a simple, synchronous solution where we had:
- A UI Client
- An API gateway to proxy the operations to the backend service
- A backend
- an Oracle database
Changing to asynchronous event-driven solution
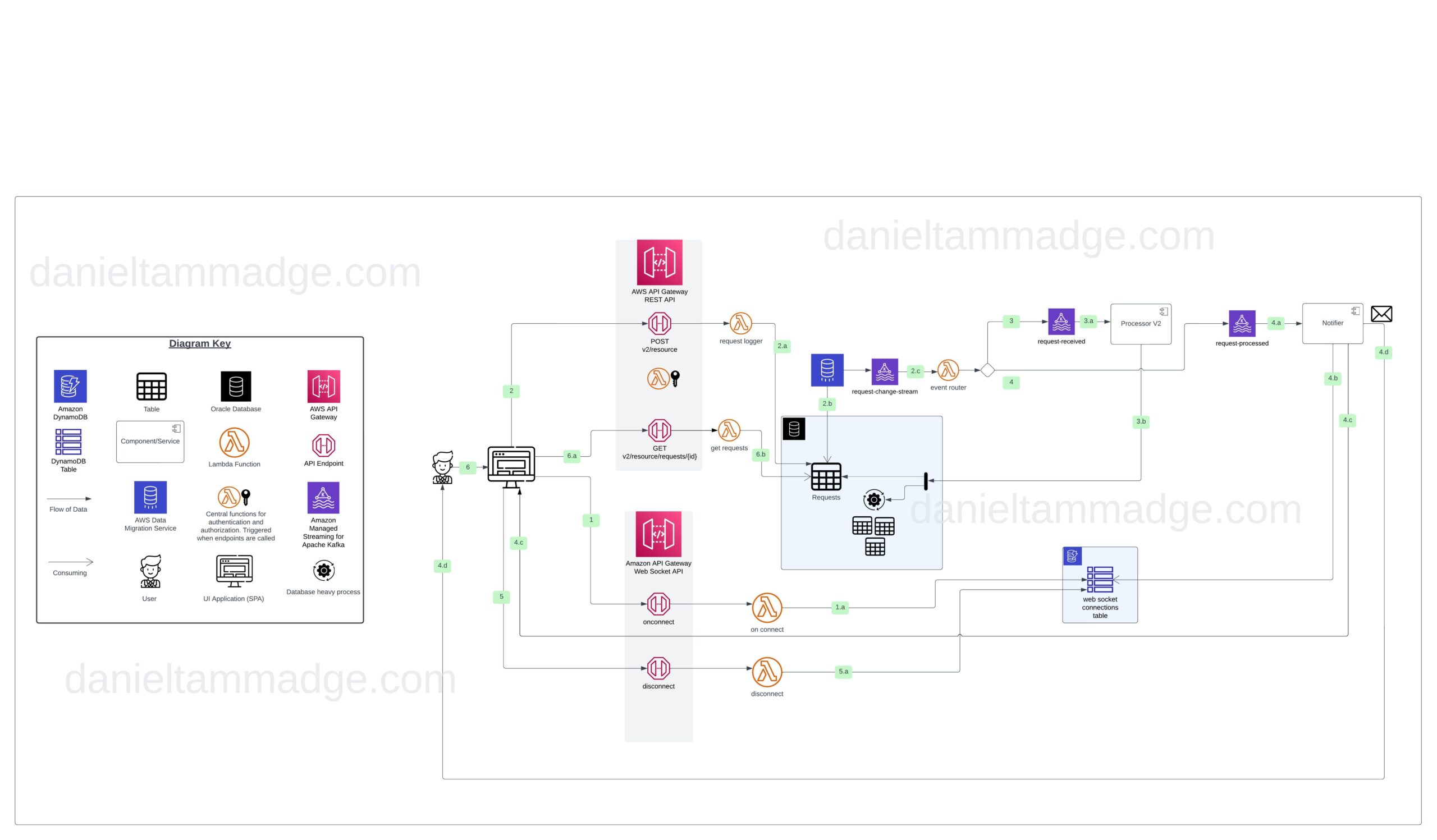
To having to change the system by adding
- two new endpoints to the API under the API Gateway
- An endpoint for version two of the operation and serving lambda function to store the request
- Another endpoint for clients to retrieve request processing results and serving lambda function to store the request
- Three Kafka Topics
- request-change-stream
- request-received
- request-processed
- A New Oracle table to log the requests and hold the processing results
- An AWS database migration service workflow to stream CDC to Kafka topic request-change-stream
- An event processor, a lambda function that consumes the request-activity-log to push events to two either of the two Kafka topics
- Stream to request-created: if the record was inserted
- Stream to request-processed: if updated and if the column “status” was updated to “processed” (using “before-image” data in the payload)
- Added a new version of the request processor to consume and process events from the request-created topic. The processor performs its database performance-heavy operations and updates the request table with the outcome within the same database transaction.
- A new lambda function to consume the request-processed event topic and notify the user who raised the request
- The function attempts to get the user’s web socket connection id if found, will notify the connected user’s client that processing has finished
- Email the user who initiated the request
- A new Web socket API under AWS API Gateway for pushing processing events to connected clients from the backend so connected. As well as
- The lambda function that serves the $connect route and stores the client details
- The lambda function that serves the $disconnect route and removes the client details from the DyanmoDB table
- A DynamoDB table to hold the web socket connected details
Architectural Design Decisions
Before describing the flow of data. A few points around the architectural decisions:
- We chose Kafka because we already use it in other places, and we required the replayability that Kafka provides because the topics are a log of immutable events.
- We decided to have the request table in Oracle and not in DynamoDB because we wanted to persist the processing outcome state to a datastore within the same database transaction, so we did not have to cater for the consequences of having distributed transactions. See my two videos on event publishing patterns.
- We knew that due to the time independence processing of event-driven systems, some requests would take longer to process than the time the user would stay on the page which provided the service. Hence there was now a new requirement which didn’t exist when the service was synchronous, as we also needed to notify users who disconnected. So we developed the ability to notify offline users via email of the processing outcome, along with the ability for them to retrieve the result at a later time.
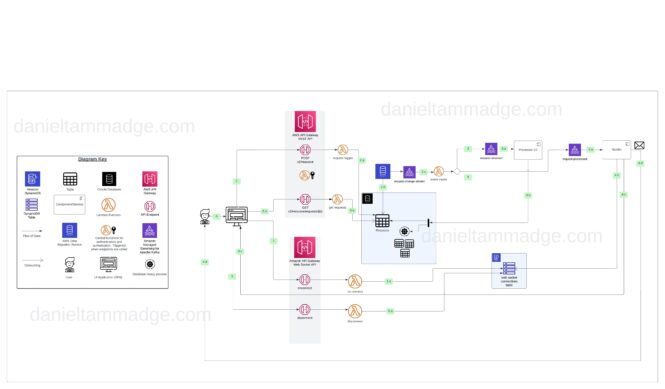
New System Diagram and Dataflow
- When the application loads, it invokes the on-connect operation with the web socket API,
- The on-connect lambda function inserts a record into the dynamo DB table for that connection.
- The request logger function is triggered when the user invokes the v2 API POST endpoint.
- The lambda function inserts a record into the request Oracle table. And the operation will return the UUID for the request back to the client.
- The AWS migration workflow, which monitors the request table, will pick up the changes and will stream them to the Kafka topic request-change-stream
- Triggering the event router Lambda function. The function will either publish an event to the request-received Kafka topic (see #3), or to the request-processed Kafka topic (see #4)
- If the event was for a new record, a request-received event is published to the request-received topic.
- Triggering the processor, which will process the requests
- and performing the required database operations, and within the same database transaction, updating the request records processing result (triggering #2.c again)
- If the event was for an updated record and the status column was changed to “processed”, a request-processed event is published to the request-processed topic
- The notifier event processor consumes the topic
- Tires to fetch a connection client record from the DynamoDB web socket connection table
- If the notifier returns that the client is still connected, Then the function will invoke POST HTTP requests to the web Socket API to invoke callback messages for the connected client using the connection identifier. The UI will present the result to the user
- The notifier emails the user
- The user leaves the UI, and the connection is disconnected
- The Disconnect Lambda function gets triggered and removes the disconnected session from the table
- If the user left the UI before the initial request was processed and did not get notified by a push, then the user may, after receiving the email navigate to the UI application and review the processing status and result
- The UI invokes a GET request to retrieve the processing results
- The Lambda function fetches and returns the processing result
Conculsion
To conclude, event-driven architecture & asynchronous communication between components require more middleware and additional design considerations and introduce complexity that doesn’t exist in synchronous request-driven solutions.