
What does the term “event-driven” mean?
What makes a system “event-driven?”
In this article, I will briefly explain five patterns that fall under the umbrella of event-driven architecture because they use events as their primary driver.
If you prefer to watch a YouTube video instead of reading this article see the YouTube version at the bottom
First Pattern: Event-Notification
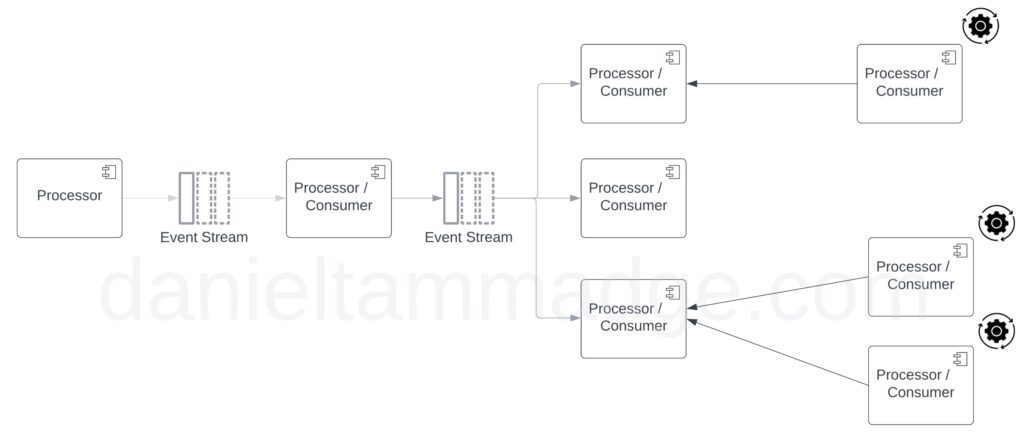
Event-Notification is using events as a notification mechanism between multiple systems.
This pattern enables components to plug on and subscribe to event streams or topics with little effort, simplifying the addition of new consumers.
Depending on the middleware, all registered consumers would be notified to trigger actions whenever an event occurs.
However, This pattern can impact performance and availability because events under the event-notification pattern do not carry state. Therefore Downstream components depend on the source systems for information.
Second Pattern: Event-Carried State Transfer
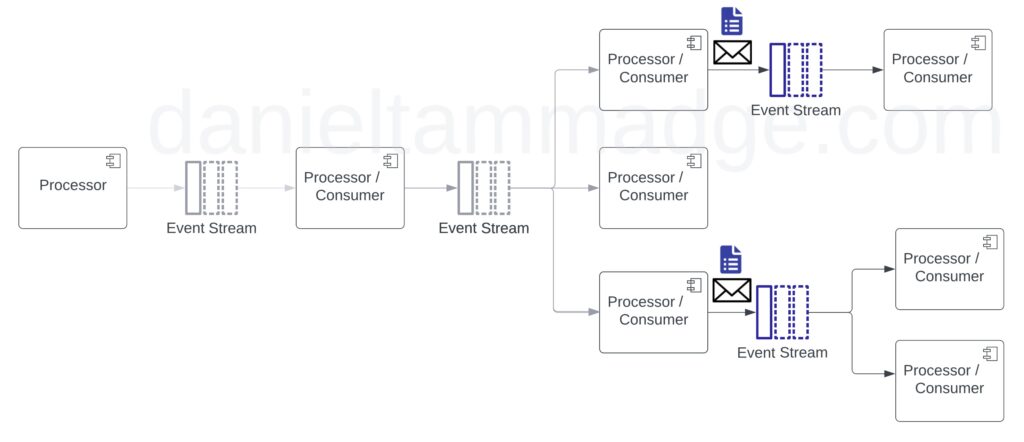
The second pattern. Event-carried state transfer is a pattern that builds on the event notification pattern by replicating all the data that downstream systems may need from the source system to avoid calling back.
This approach can help improve performance and availability, as downstream systems no longer depend on the source system.
However, it can also lead to potential consistency issues because
- event state could be stale by the time a consumer processes the event data
- And due to latency and distributed systems, we have eventual data constancy
Third Pattern: CQRS
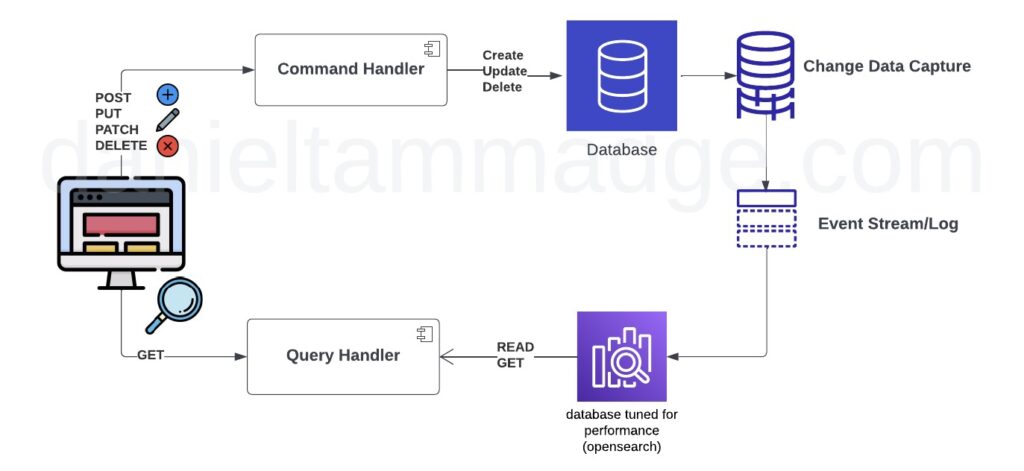
The Third pattern CQRS (Command Query Responsibility Segregation), is a pattern that involves separating the processing of commands or events that update entities from the processing of queries.
This approach can help improve performance and scalability, allowing different processing pipelines to be optimisede for their specific tasks. The idea is to use a separate process for read and write operations, each optimised for their specific task. The writing process is typically used to CREATE, UPDATE & DELETE objects and is optimised for consistency, while the READ model is used to query the state and is tuned for performance. By separating the two, CQRS can help improve scalability, as the read-and-write models can be scaled independently. However, it can also lead to increased complexity, as there are now two separate pipelines to manage.
## Fourth Pattern: Event-Sourcing
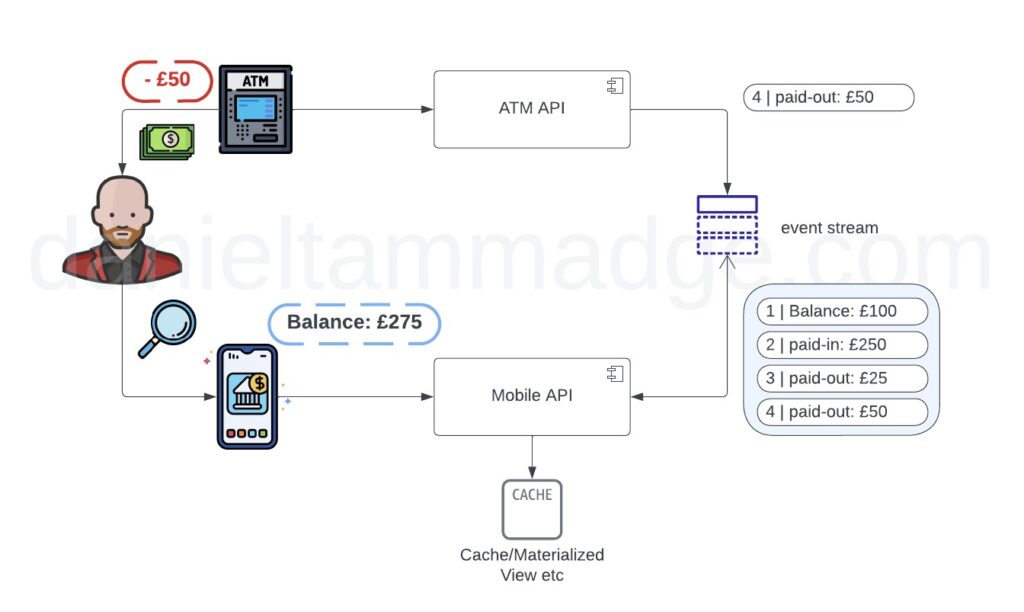
The Fourth Pattern. Event sourcing is a pattern that involves creating an immutable activity log of all the events that change the state of business objects.
Instead of storing and maintaining the current state of the system or objects at all times, event-sourcing treats events as the source of truth for the system or objects by deriving the state from the stream of events.
Unlike the Command Query Responsibility Segregation pattern, which supports the full range of CRUD operations against objects. Event-Sourcing pattern only supports CREATE & UPDATE, in the sense that rather than making changes to objects/records, you CREATE a record in a log, Just like a finance ledger.
These events, these log records, can be replayed to reconstruct the system’s current state at any point in time.
Now the purists will tell you that using the event logs to build and maintain temporary long-term materialised views, or even local copies of data for quick access, goes against the concept of event-sourcing. However, I believe you do whatever you need to meet your performance, reliability and scalability requirements. Building state from an event log on request can be costly.
Event sourcing allows for greater flexibility and scalability, as copies of data can be rebuilt from the log anytime.
Also, It provides a complete audit trail of all changes made to the system, which can be helpful in specific scenarios, such as compliance requirements.
However, implementing it can be complex, as it requires careful consideration of how events are logged and how the application state is derived from them.
But do not mistake Event-Sourcing for Event-Streaming.
Fifth Pattern: Event-Streaming
And the fifth pattern is Event Sourcing, Now, I originally intended to discuss Event-streaming under the second pattern Event-Carried State, but Event-Streaming is a pattern in its own right and requires its own mention.
I think of event-carried-state as a process or system, handing the baton over to another process or system. In contrast, Event-Streaming is the mindset to take when architecting or choreographing a low latency, near-real-time data processing pipeline. For example, the triggering of single-purpose functions that process, filter and split events downstream.
And the industry uses event streaming for financial data processing, field detection
Event-Streaming often gets confused with Event-Sourcing.
Both require a stream, or a log, of immutable events retained for a certain period. And in my experience, enabling one enables the other. However, they are not the same.
Event-Streaming opens up connectivity and allows events to reach multiple destinations by enabling multiple functions, services and systems to consume an event stream and process the events independently to drive their processes.
In Event-streaming, an event state is stale as it flows through a pipeline. In comparison, Event-sourcing purpose is to ensure that the state of an entity is kept up to date by using the events.
I have heard the following to describe the difference:
Event-Sourcing is data-at-rest, while event-streaming is data-in-motion.
Call to action
Now go and check out the post comparing the difference between two types of middleware which enable event-driven architecture, event streams and message brokers.